
特别注意,本次教学是已经默认你已经拥有一定的python语法基础和HTML知识的前提下进行的!!!
首先,我默认各位已经安装了pycharm环境,如果安装了anaconda更好,没有安装问题也不大,可以点击这里来进行环境的安装,现在让我们写出你人生中第一个爬虫程序吧!!!!
要爬的网站豆瓣TOP250
我们这次要爬的就是这么一个界面
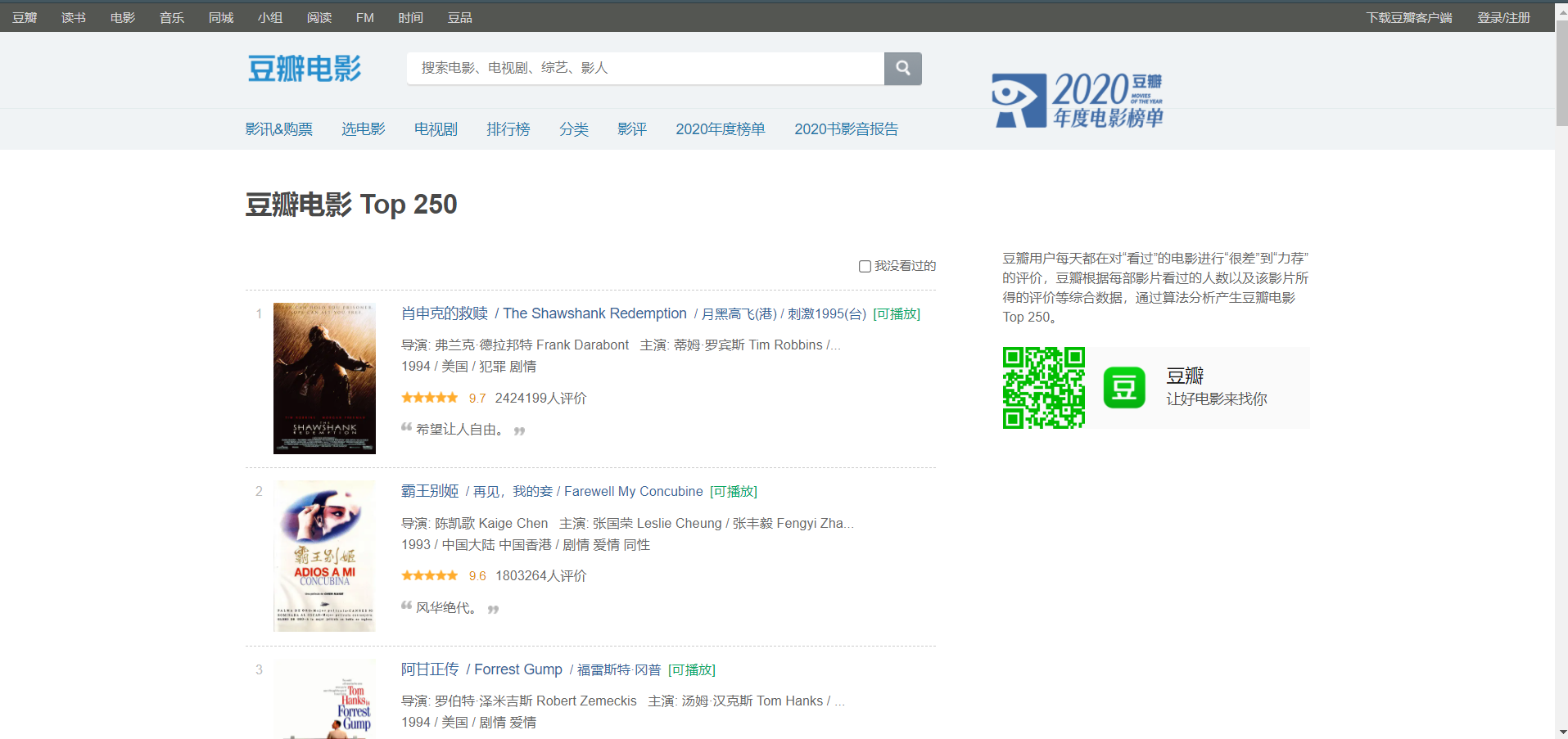
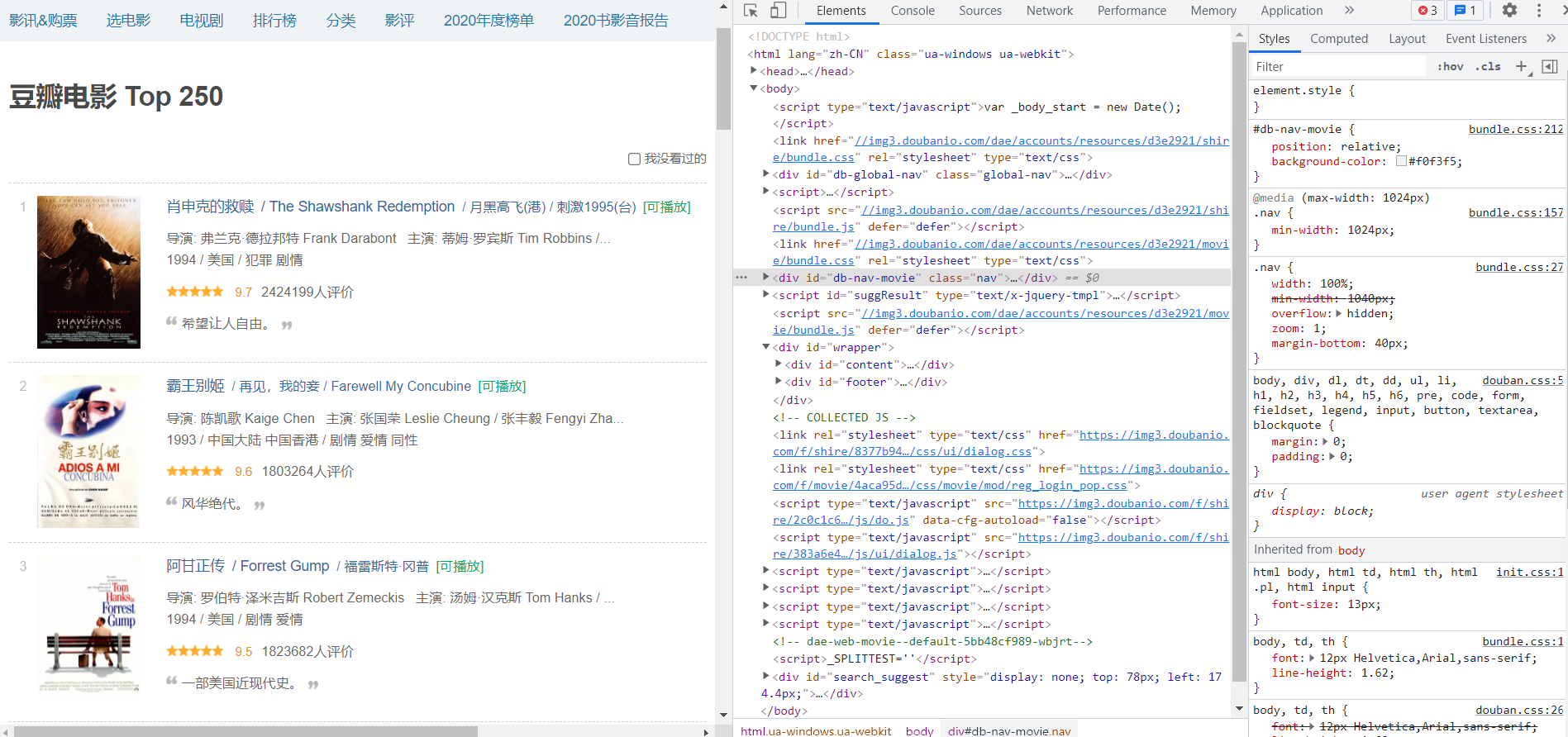
准确来说是这个界面的HTML代码,可以打开F12进行查看
现在,我们打开pycharm,新建文件(我相信各位都会),导入requests包,如果用的anaconda的同学会发现已经自带了,如果没有的话可以自行搜索如何去安装,并在url中储存豆瓣TOP250的链接
import requests
url = 'https://movie.douban.com/top250'之后,我们在返回页面,检查网页源代码,发现它是已GET方式进行传输的
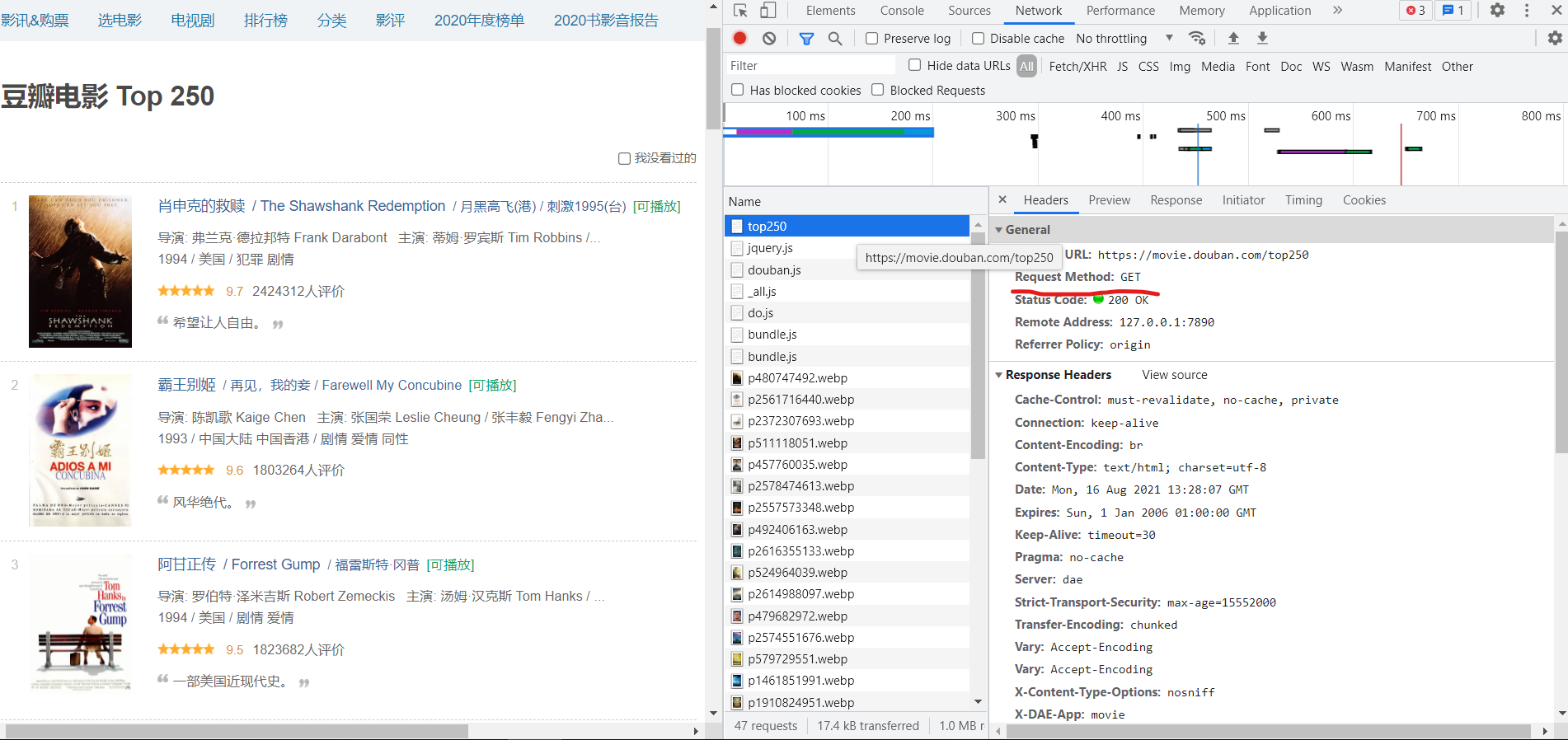
这时候,我们就可以通过resquest来获取网页源代码
import requests
url = 'https://movie.douban.com/top250'
response = requests.get(url = url)这时候的response还不能被我们所看懂,需要转换成text才可以,之后再输出
import requests
url = 'https://movie.douban.com/top250'
response = requests.get(url = url)
html = response.text
print(html)这时候查看输出
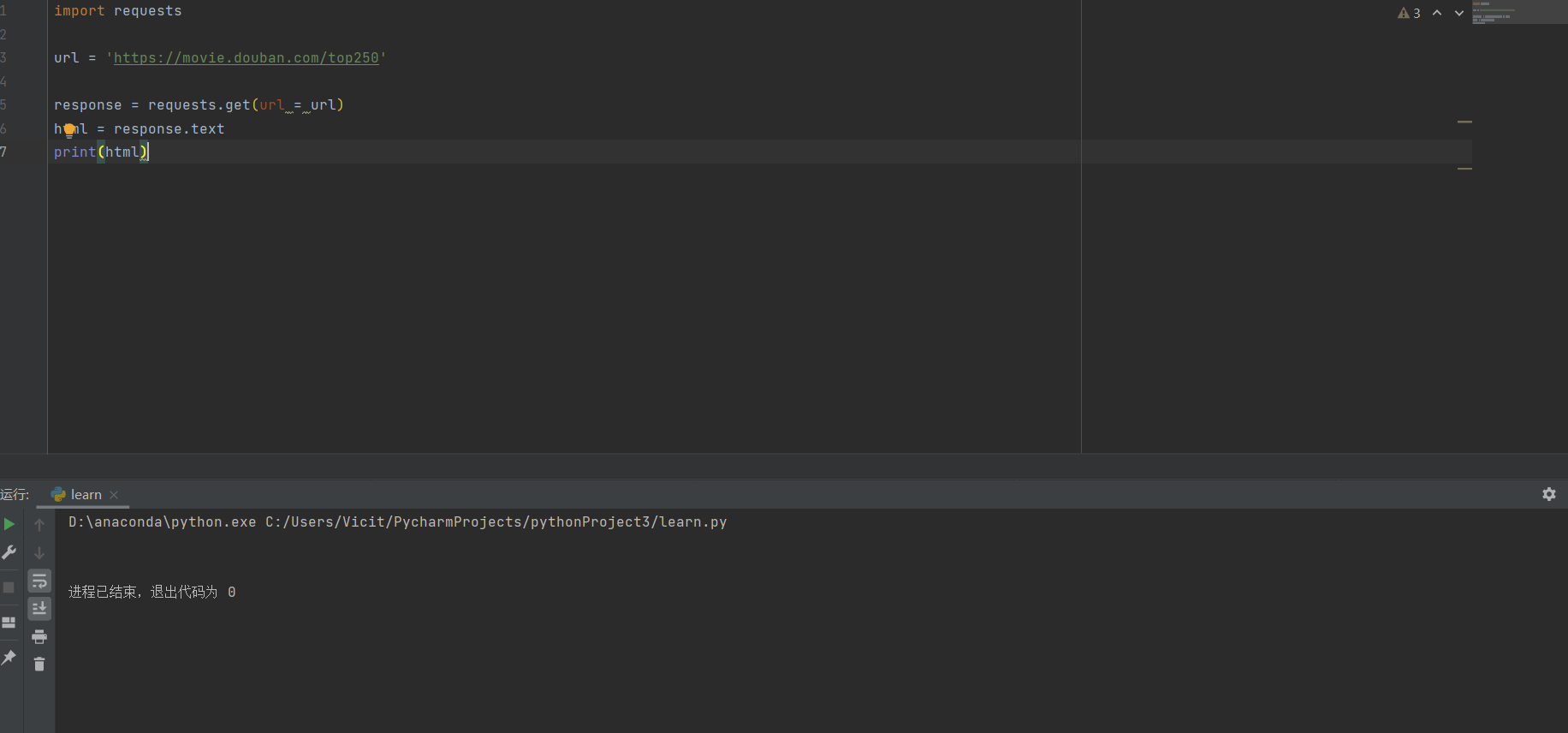
这时候你会发现,它什么也没有输出,这时候,我们就要了解一下resquest方法了,如果可以了解它,各位就能破解很多一部分反爬问题了,它不仅需要网页链接,还需要模拟计算机登录的参数以及GET所需的参数(本文暂不涉及),而我们该如何模拟计算机登陆呢?
这时候我们需要再次打开浏览器检查代码
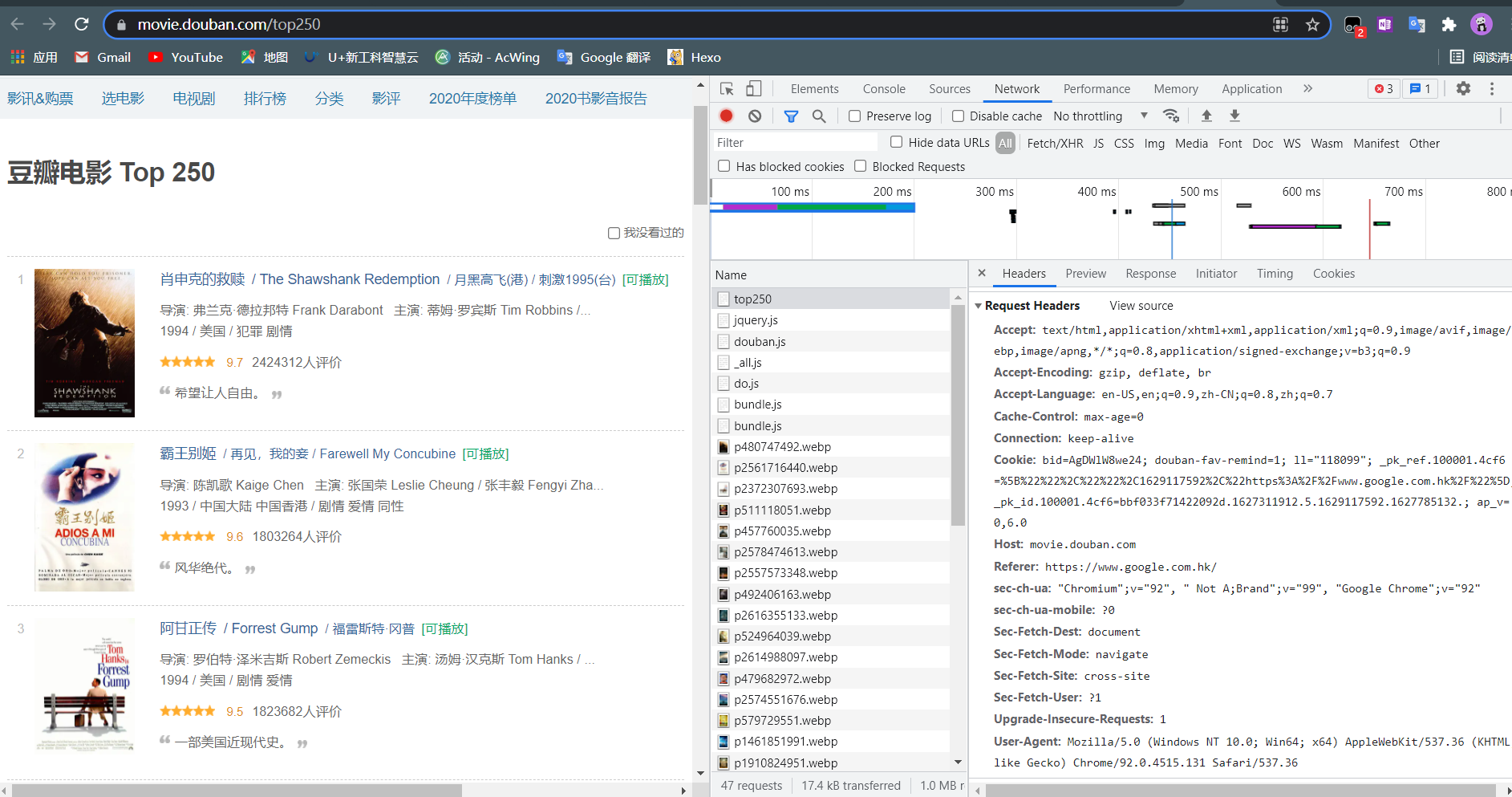
发现右下角有一个User-Agent,这个就是我们每次登录网页时计算机所提交的参数,用于证明我们是人为使用浏览器登陆的,如果不加,网页会很快识别我们为爬虫将我们拦截,所以我们要以字典的方式将它写入resquest中
import requests
url = 'https://movie.douban.com/top250'
head = {
"User-Agent": "Mozilla / 5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 92.0 .4515 .107 Safari / 537.36"}
response = requests.get(url = url, headers = head)
html = response.text
print(html)再一次运行程序
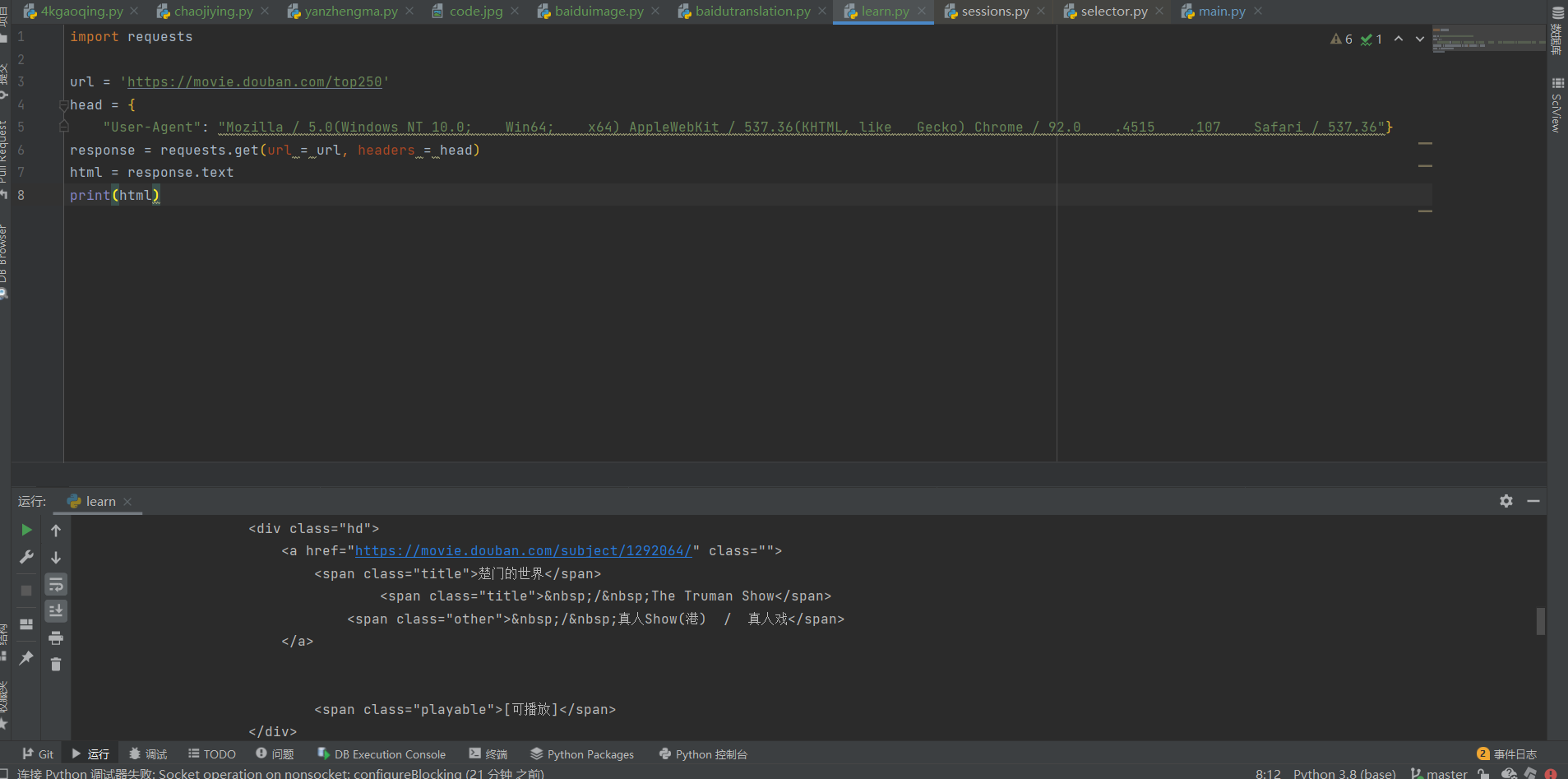
发现这次成功返回我们想要的第一页网页源代码了。
如果各位成功了,那么恭喜,各位的第一个爬虫程序已经成功面世了。
一个各位可能遇见的问题
如果各位程序没有错误,但又报以下的错误
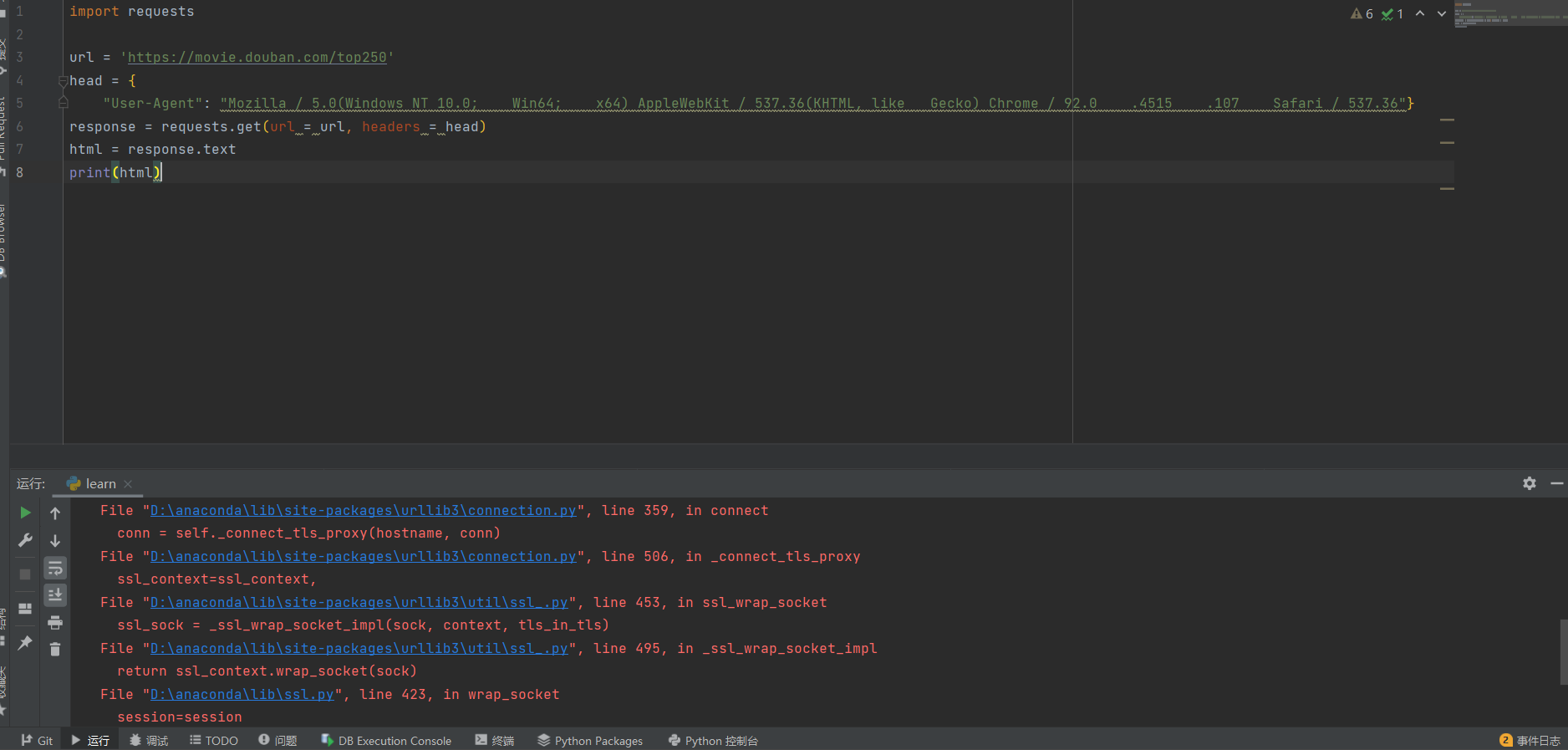
ValueError: check_hostname requires server_hostname
那么可各位在运行时开着网络代理(俗称梯子),只要关闭代理,就可以正常使用了
如果各位遇到问题,可以通过加我微信或者B站私信问我,我可以解决的一定会尽力帮助大家的。
text